Vous souhaitez récupérer des données présentes sur un fichier PDF ? En effet, il n’est pas toujours simple de récupérer des données présentes sur ce type de fichier. Voyons une solution qui devrait pouvoir répondre à ce besoin.
Extraire des données avec Tabula
Si vous avez déjà essayé de récupérer des données depuis des fichiers PDF, vous devez savoir combien cela peut-être pénible…
En effet, il n’existe pas de moyen simple de faire un « copier-coller » des lignes de données à partir de fichiers PDF.
Cependant, la solution Tabula nous permet d’extraire ces données dans un fichier de type CSV ou Microsoft Excel. Cela à l’aide d’une interface simple et conviviale à utiliser. A savoir que Tabula est une solution gratuite qui fonctionne sur Mac, Windows et Linux.
Utilisation de Tabula
Une fois que vous avez téléchargé et installé Tabula, il vous suffit de procéder comme suit pour récupérer les données d’un fichier PDF :
1 – Téléchargez un fichier PDF contenant une table de données.
2 – Naviguez jusqu’à la page souhaitée, puis sélectionnez le tableau en cliquant dessus et en le faisant glisser pour dessiner un cadre autour du tableau.
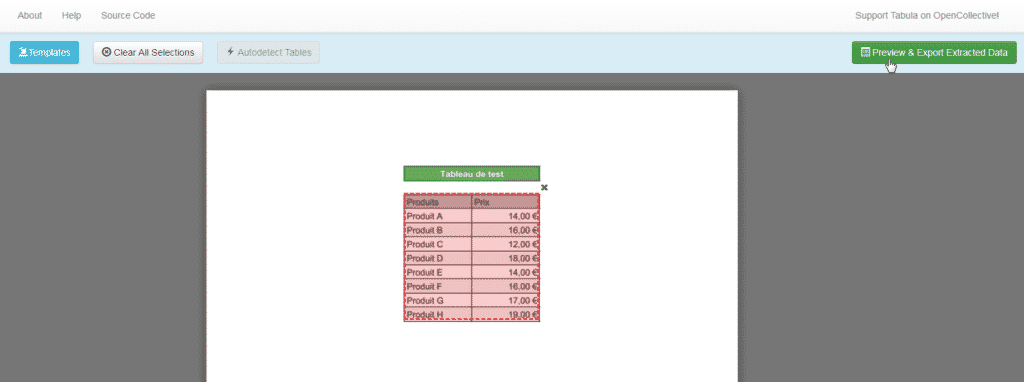
3 – Cliquez sur « Aperçu et exportation des données extraites ». Tabula essaiera d’extraire les données et d’afficher un aperçu.
Inspectez les données pour vous assurer qu’elles semblent correctes. Si des données sont manquantes, vous pouvez revenir en arrière pour ajuster votre sélection.
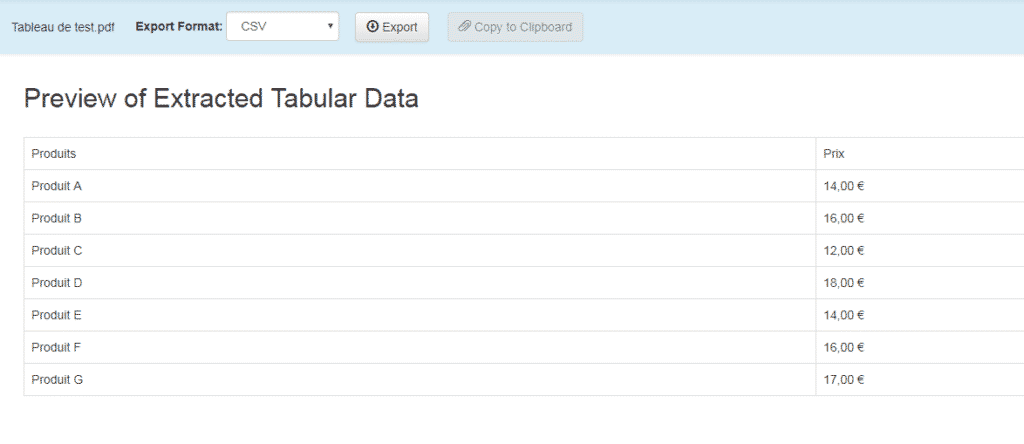
4 – Cliquez sur le bouton « Exporter ».
5 – Vous pouvez maintenant utiliser vos données sous forme de fichier texte ou de feuille de calcul plutôt que de PDF! (Vous pouvez alors ouvrir le fichier téléchargé dans fichier de type Tableur comme Sheets, Excel, Calc, …)
Conclusion
J’espère que cette information vous permettra de gagner du temps ! Merci aux créateurs de ce logiciel très pratique pour récupérer des données provenant de fichiers PDF.
Vous avez testé la solution ? N’hésitez pas à donner votre avis sur celle-ci dans les commentaires ci-dessous !
À bientôt ! 🙂